GitHub - Anjok07/ultimatevocalremovergui: GUI for a Vocal Remover that uses Deep Neural Networks.
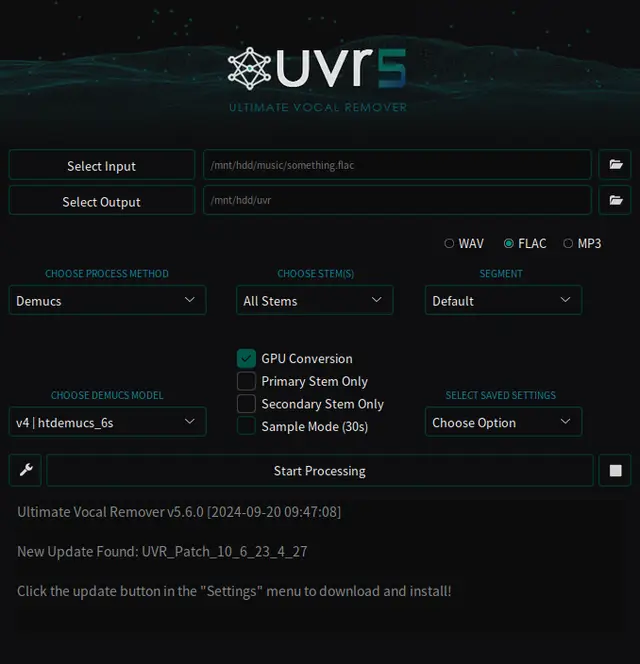
ひとつの音声ファイルから、ベースやギター、ボーカルなど、パート毎に音声を分割することができる。
UVR は、それ自体には音声を解析・処理する能力を持っていない。 音声の解析に使う学習モデルを別途ダウンロードする必要があって UVR はあくまでそのクライアントアプリケーションだ。 モデルのダウンロードも UVR 上で行える。
UVR が対応している学習モデルは MDX と Demucs の 2 種類。 学習の規模やふるまいの違いから、MDX にも Demucs にも複数のバージョンが存在する。
私は、ボーカル / ピアノ / ギター / ベース / ドラム / その他の 6 つに分割できる、 Demucs の v4 htdemucs_6s というモデルを使っていて、今のところ満足している。 比較したわけではないので、より優れたモデルがあるかもしれない。
実用に足る精度で分割できる。 ベースのハイフレットの音がギターとして認識されたり、ギターの歪の高い音が「その他」として扱われたりと、完璧には程遠い。 ベース以外の音声ファイルにもベースの音が含まれるので、音作りの参考にするときには注意が必要だ。 とはいえ、コピーやバックトラックを作る用途では十分以上の精度だと思う。
似たようなツールは他にもあって、Web なら Splitter AI, Voice.ai, LALAL.AI、モバイルなら Moises が良さそう。